The meta element
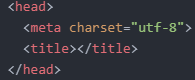
- Tells the browser how it should display the webpage
- Can also give info to search engines about the content of the website (author, description, keywords etc.)
- charset = character set
- In the above case, we're telling the browser that the text inside the webpage is encoded using the UTF-8 system
- UTF-8 is the standard when working with HTML5. Basically a list of all the available characters that we can use for it to be rendered correctly.
Unicode and character sets
- Good old unaccented English letters = ASCII
- Represented every character using a number between 32-127. Space was 32, “A” was 65, etc.
- Codes below 32 were used for control characters, e.g., 7 made your computer beep
- Could be stored in 7 bits (computers in those days were using 8-bit bytes)
- Eventually came the ANSI standard (everyone agreed on 👆ASCII, but differed from 128 up)
- The different systems were called code pages (e.g. Israel used CP 00862, while Arabic used CP 00864)
- Then there came Unicode
- A brave effort to include every reasonable writing system on the planet
- Every platonic (first principle) letter in every alphabet is assigned a number by the Unicode consortium, written: U+0639. This is called a code point. U+ => “Unicode” and the numbers were hexadecimal (using base 16 instead of the normal base 10)
There were arguments over how to store these code points.
There are over a hundred encodings and above code point 127, all bets are off.
UTF-8 is a method of storing (encoding) unicode code points.
We use the charset attribute because it does not make sense to have a string without knowing what encoding it uses